Ask GPT
Ask a question to a selected GPT model and return the answer.
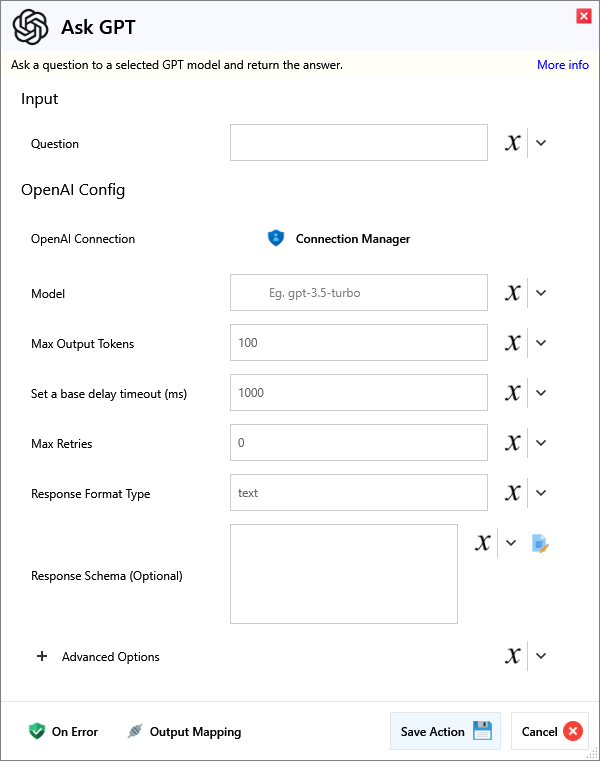
Input
Input
| Name | Required | Description |
|---|---|---|
| Question | The question you would like to ask GPT. |
OpenAI Config
| Name | Required | Description |
|---|---|---|
| OpenAI Connection | ||
| Model | Enter a valid model to be used. (See OpenAI API Docs) | |
| Max Output Tokens | Maximum number of tokens for the output. Make sure this, combined with your input, does not exceed the model's limit. This also limits reasoning tokens for o1-preview, o1-mini, etc. | |
| Set a base delay timeout (ms) | Set base delay to wait, before doing another request. | |
| Max Retries | Maximum number of requests to send, before stopping. | |
| Response Format Type | Options are text, json_object (to enforce valiud JSON), and json_schema (enables Structured Outputs to match schema). | |
| Response Schema (Optional) | If Response Format Type is json_schema, this is used to force output into this format. |
Advanced Options
Advanced Configuration
| Name | Required | Description |
|---|---|---|
| Temperature | Sampling temperature between 0 and 2. Higher values make the output more random, while lower values make it more focused and deterministic. | |
| Presence Penalty | Number between -2.0 and 2.0. Positive values penalize new tokens based on their presence in the text so far, encouraging new topics. | |
| Frequency Penalty | Number between -2.0 and 2.0. Positive values penalize new tokens based on their frequency in the text so far, reducing repetition. | |
| Stop Sequences | Up to 4 sequences where the API will stop generating further tokens. The returned text will not contain the stop sequence. | |
| Top P | Nucleus sampling alternative to temperature. Considers tokens with top_p probability mass. For example, 0.1 means only tokens in the top 10% probability mass are considered. | |
| Logit Bias | JSON object mapping token IDs to bias values (-100 to 100) to modify the likelihood of specified tokens appearing in the completion. Eg. {2435:-100, 640:-100} |
Output
| Name | Required | Description |
|---|---|---|
| Action Success | True if the action passed, false if it failed. | |
| GPT Answer | The answer returned by GPT. | |
| Finish Reason | The reason ask GPT finished (e.g. length when max tokens is hit). |
|Status Code| |The HTTP status code of the response.| |Request Success| |True if the request was successful.| |Error Message| |The error message for an unsuccessful request.|